
Banco Vetorial: Qdrant + Spacy introdução
Introdução
Com o avanço da inteligência artificial e da ciência de dados, a busca e o armazenamento de informações evoluíram significativamente. Um exemplo disso é o surgimento dos bancos de dados vetoriais, projetados para lidar com vetores de alta dimensão, fundamentais em aplicações que utilizam aprendizado de máquina, como busca semântica e sistemas de recomendação.
Neste artigo, exploraremos:
- Um exemplo prático utilizando spaCy (https://spacy.io/) e Qdrant (https://qdrant.tech/).
- O que é um banco de dados vetorial.
- Suas principais aplicações e vantagens.
O que é um Banco de Dados Vetorial?
Um banco de dados vetorial é um sistema especializado em armazenar e consultar vetores de alta dimensão. Esses vetores são representações numéricas de dados, gerados a partir de técnicas de aprendizado de máquina, como transformers e modelos de embeddings. Os bancos de dados vetoriais são um componente essencial para lidar e consultar eficientemente dados vetoriais em larga escala, o que pode melhorar o desempenho de aplicativos que aproveitam os LLMs. Isso porque os dados vetorizados, transformados em dados numéricos, podem ser processados mais rapidamente do que qualquer outro tipo de dados, além disso, pode-se realizar operações matemáticas, no caso, pode-se calcular, por exemplo, distancias entre os vetores em um espaço euclidiano.
Principais características:
- Busca Semântica: Recupera informações similares em um espaço vetorial, ao invés de depender de correspondências exatas.
- Alta Dimensionalidade: Trabalha com vetores de dezenas, centenas ou milhares de dimensões.
- Distâncias Métricas: Utiliza métricas como cosine similarity, distância euclidiana ou Manhattan para calcular proximidades entre vetores.
- Para mais sobre distancia cosine: https://medium.com/@milana.shxanukova15/cosine-distance-and-cosine-similarity-a5da0e4d9ded
Como funciona a busca vetorial?
- Primeiro, os dados são armazenados como conjunto numérico, representando a informação;
- A busca é feita por similaridade, montando-se um gráfico e usando-se um modelo de distancia, sendo que a distancia cosine é uma das preferidas.
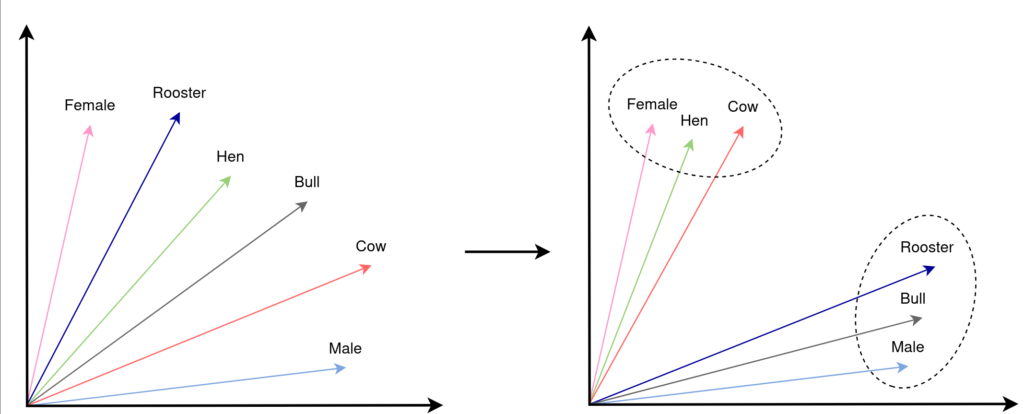
Aplicações:
- Motores de busca semântica (como sistemas de recomendação).
- Detecção de anomalias e classificação.
- Processamento de linguagem natural (NLP) e visão computacional.
Exemplo Prático: Busca Semântica com spaCy e Qdrant
Contexto
Neste exemplo, simularemos um sistema de recomendação de livros com base em suas descrições. Utilizaremos:
- spaCy: Para gerar vetores das descrições dos livros.
- Qdrant: Para armazenar e consultar esses vetores.
- Pandas e Matplotlib: Para visualização e análise.
Passo a Passo
1. Configuração Inicial
Instale as dependências necessárias:
pip install spacy qdrant-client pandas matplotlib scikit-learn
python -m spacy download pt_core_news_md
2. Carregando o Modelo spaCy
import spacy
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct, VectorParams, Distance
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Carregar o modelo spaCy
nlp = spacy.load("pt_core_news_md")
# Inicializar o Qdrant
client = QdrantClient(":memory:") # Armazenamento em memória
3. Criando a Base de Dados dos Livros
Defina uma lista de livros com suas descrições:
documents = [
{"name": "A Máquina do Tempo", "description": "Um homem viaja pelo tempo e testemunha a evolução da humanidade.", "author": "H.G. Wells", "year": 1895},
{"name": "O Senhor dos Anéis: A Sociedade do Anel", "description": "Um hobbit embarca em uma jornada perigosa para destruir um anel que possui poderes malignos.", "author": "J.R.R. Tolkien", "year": 1954},
# Adicione mais livros...
]
4. Inserindo Dados no Qdrant
Transforme as descrições dos livros em vetores e armazene-os:
def ingest_data(documents, client):
embeddings = []
for i, doc in enumerate(documents):
vector = nlp(doc["description"]).vector
point = PointStruct(
id=i,
vector=vector,
payload=doc
)
embeddings.append(point)
client.create_collection(
collection_name="books",
vectors_config=VectorParams(size=len(embeddings[0].vector), distance=Distance.COSINE),
)
client.upsert(collection_name="books", points=embeddings)
print("Dados ingeridos com sucesso!")
ingest_data(documents, client)
5. Realizando Buscas Semânticas
Utilize a consulta para encontrar livros relacionados:
def search_qdrant(query, client, top_k=3):
query_vector = nlp(query).vector
search_result = client.search(
collection_name="books",
query_vector=query_vector,
limit=top_k
)
return [hit.payload for hit in search_result]
query = "Jornada épica com anéis mágicos"
results = search_qdrant(query, client)
print("Resultados da busca:")
for result in results:
print(result)
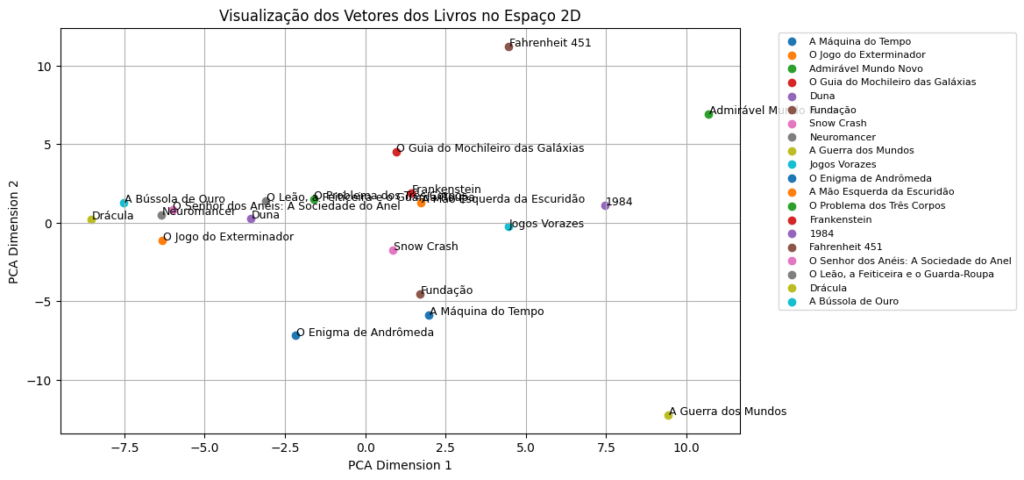
6. Visualizando os Vetores
Reduza as dimensões dos vetores para 2D com PCA e plote-os:
vectors = [nlp(doc["description"]).vector for doc in documents]
pca = PCA(n_components=2)
reduced_vectors = pca.fit_transform(vectors)
plt.figure(figsize=(10, 6))
for i, vector in enumerate(reduced_vectors):
plt.scatter(vector[0], vector[1])
plt.text(vector[0] + 0.02, vector[1] + 0.02, documents[i]["name"], fontsize=9)
plt.title("Visualização dos Vetores dos Livros no Espaço 2D")
plt.xlabel("PCA Dimensão 1")
plt.ylabel("PCA Dimensão 2")
plt.grid(True)
plt.show()
O Gráfico a seguir, possibilita a visualização dos livros, em um espaço vetorial.
Conclusão
Os bancos de dados vetoriais, como o Qdrant, são ferramentas poderosas para armazenar e consultar vetores em aplicações modernas de IA. Com o exemplo acima, mostramos como criar um sistema simples de busca semântica baseado em descrições de livros. Esse conceito pode ser expandido para várias áreas, incluindo recomendação de produtos, busca em documentos e muito mais.
Esperamos que este artigo tenha sido útil para introduzi-lo ao mundo dos bancos de dados vetoriais! Caso tenha dúvidas ou sugestões, deixe um comentário.
O código completo está disponível no colab: https://colab.research.google.com/drive/1tBD76jwK0cOtPZY8C7y_Z13cgifcSBDh?usp=sharing


Publicar comentário